The goal of this component is to formalize human tacit knowledge and make it available to other software components. This will be done by generating machine-processable rules based on spoken input. In addition, the knowledge base will be extended by the "discovered" rules, while at the same time ensuring the consistency of the knowledge base (e.g., avoiding contradictory rules).
The component will be realized by combining three different types of technologies and by using commodity software:
In – spoken text
Out -rule(s)
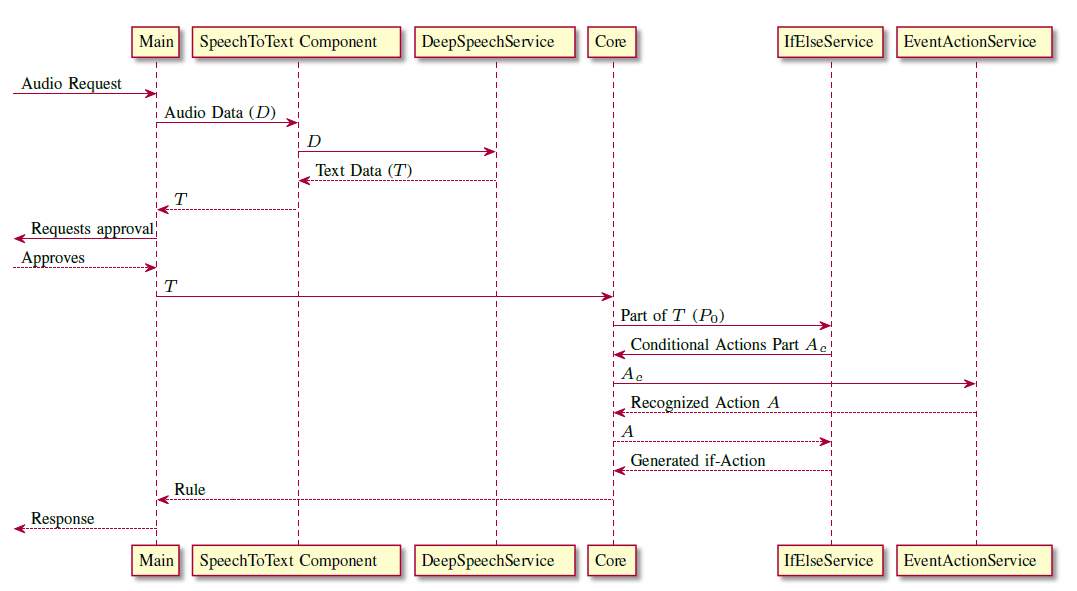
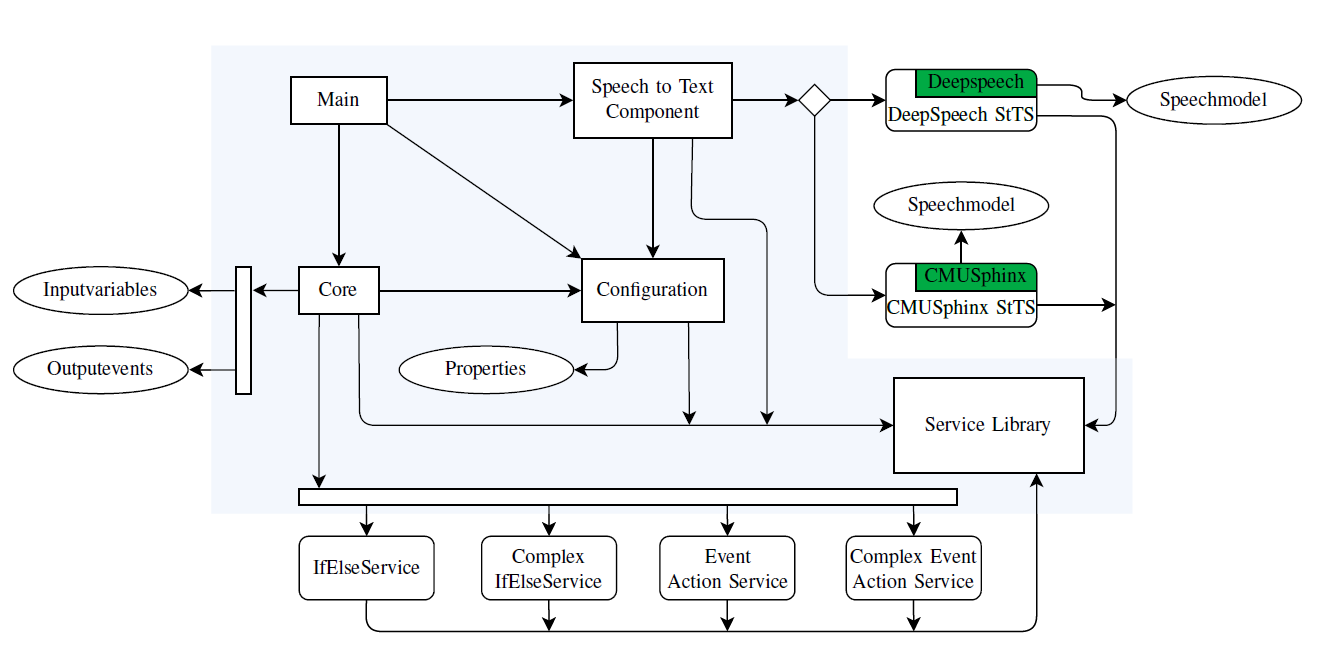
SpinPro is divided in several components as illustrated in Figure below. The process is split into two parts, the speech recognition and the rule creation. Each part is capsulated in one program component. The speech recognition is performed in the Speech to Text component (StTC) and the rule creation in the Core component (Core). The Main component (MC) manages the StTC and the Core. Furthermore, the MC provides the APIs for user interaction and contains the entry point of SpinPr. Those three components use a fourth component called Configuration component (Config). The Config provides a logging framework, the application preferences and messages in multiple languages used as error and logging messages. Moreover, the Config contains a framework for the loading of services. Services are user definable and exchangeable components, that are loaded at the start of the application. The Core and the StTC both use services in order to maximize customizability. All services and all components, besides the MC, use a fifth SpinPro component called Service Library (SL). The SL provides the definitions for all interfaces used in services. Furthermore, it contains definitions of the predefined actions and several parsers for arithmetic and Boolean expressions as well as for parsing single variables and events.
1. Librispeech: An ASR corpus based on public domain audio books. Panayotov, V., et al. 2015. 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). ss. 5206-5210.
2. RETURNN as a generic flexible neural toolkit with application to translation and speech recognition. Zeyer, Albert, Alkhouli, Tamer og Ney, Hermann. 2018.
3. Wang, Yiming, et al. Espresso: A Fast End-to-end Neural Speech Recognition Toolkit. Espresso: A Fast End-to-end Neural Speech Recognition Toolkit. 2019.
4. Povey, Daniel. Kaldi. Kaldi. [Internett] 2020. https://kaldi-asr.org/.
5. Inc., Alpha Cephei. Vosk. Vosk. [Internett] 2020. https://alphacephei.com/en/.
Frameworks